Project Description
League of Legends (LoL) is the most popular Multiplayer Online Battle Arena (MOBA) at this time, developed by Riot Games. Most of LoL’s success is due to its competitive ranked gameplay where two teams of five players fight against each other to destroy the other team’s base.
In this project, we use various machine learning models that can predict the outcome of the ranked LoL match. Given that early-game performance often sets the tone for the match, the project focuses on early-game statistics to see how well they predict the outcome. With a predictive accuracy of over 80%, the model highlights that team advantage in the early stages can significantly forecast match results.
Dataset
The data was gathered from Riot Games’ public API, covering over 25,000 ranked matches played by competitive players. Key features include:
- Gold: Reflects the in-game currency earned by a team, used to enhance player power by purchasing items.
- Experience (XP): Indicates the total experience points a team accumulates, affecting the players’ level and in-game strength.
- Dragons Killed: Represents the number of dragons defeated by each team, with specific types (like Fire, Earth, and Water) granting different strategic advantages.
- Inhibitors Destroyed: Counts the number of inhibitors broken by the opposing team, which can significantly impact game progression.
Feature Selection
Feature selection was essential to build an effective predictive model.
Using Pearson’s R-correlation, the project identified that the features
most correlated with winning outcomes were gold, experience, dragon kills, and
inhibitors destroyed.
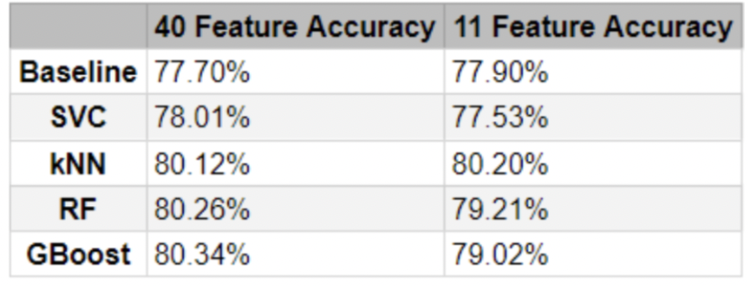
Additional analysis reduced the feature set from
40 down to 11, eliminating redundant features like kills and assists that could be
derived from other data points. By simplifying the model to focus on these
top predictors, the model improved both in accuracy and interpretability, with these
key metrics emerging as reliable indicators of match success in the early game.
Predictive Task and Model
The main goal was to predict the winning team based on early-game data.
The dataset was divided into a training set (80%) and a test set (20%)
to evaluate performance. Several machine learning models were tested:
- Basic Logistic Regression Classifier (Baseline)
- Support Vector Classifier (SVC)
- Random Forest (RF)
- Gradient Boosting (GBoost)
- k-Nearest Neighbors (kNN)
EDA
EDA was conducted to understand how specific metrics differed between
winning and losing teams within the first 15 minutes. Analysis showed that
winning teams typically accumulated higher average gold
and experience points. Winning teams also
excelled in securing objectives, destroying significantly more dragons and turrets
than their opponents.
Additional features, such as average kills, were also higher
for winning teams, indicating that early advantages in resources and objectives lead to higher win probabilities.
This analysis confirmed that early-game performance can be a strong indicator of the match outcome and reinforced the
importance of the chosen features in predicting winners.
Conclusion
The project successfully demonstrated that early-game metrics could predict the outcome of a League of Legends match with over 80% accuracy.
The final model, a k-Nearest Neighbors (kNN) classifier, was both effective and efficient,
maintaining high accuracy while using fewer features than other models tested.
By focusing on just a few critical metrics like gold, experience, and objectives achieved (dragons and inhibitors destroyed),
the project showed that early-game performance is crucial in competitive matches. Future improvements could include
incorporating player-specific skill metrics to enhance accuracy further, as studies show this data may offer additional predictive value.